
General Database Design Guidelines and Naming Conventions
Here are some helpful tips on database naming conventions. Consistency, readability, maintainability, and extensibility are some of the most important factors when designing new databases. In this blog I’ll go over some conventions I use to keep myself consistent. If you have any conventions you follow or ways to improve these conventions, let me know. :)
Entity Class Naming
The name of our entity classes should be in the singular form, for
example Account, Customer, or User (for a user accounts
table). Plural names (such as Accounts, Orders, and Order Details)
aren’t good candidate for entity names because 1) plural names don’t
grammatically fit well when reading relationships that are
self-referencing and one-to-one 2) it reduces the readability of SQL
statements when fully qualified names the WHERE clause. To Illustrate:
/* Using singular form */
SELECT * FROM Account WHERE Account.ID = 1;
/* Using plural form */
SELECT * FROM Accounts WHERE Accounts.ID = 1;
If you ask me, the singular form reads much better in the WHERE clause, but the plural form performs better in the FROM clause. When creating complex SQL queries, readability in the WHERE clause tends to outweigh the benefits of readability in the FROM clause. This is why singular table names are generally better. Furthermore, the name of the entity should be representative of a single row in the table. Names like History, Schedule, and Table are not descriptive enough.
For certain types of entities, special keywords should be contained in the naming of the entity. Below is a list of special entities and associated key words that should be considered a part of the naming scheme.
- Tracking History: History, Historical, Event
Attribute Naming
Below is a small list of naming guidelines for naming columns based on the type of data they hold.
- Identifiers: Number (or No), Code, Identifier (or Id), Tie-Breaker
- Categories: Type, Method, Status, Reason
- Counts: Count
- Dimensions: Length, Width, Height, Weight
- Amounts: Amount, Price, Balance
- Factors: Rate, Concentration, Ratio, Percentage
- Specific Time Points: Timestamp, DateTime, Date, Month, Year
- Recurrent Time Points: TimeOfDay, DayOfWeek, DayOfMonth, DayOfYear, MonthOfYear
- Intervals: Duration, Period
- Positions: Point, LineSegment, Polygon
- Texts: Name, Description, Comment, Instructions
Try to avoid abbreviations; it may likely confuse business people using the database.
Natural Keys vs Surrogate Keys
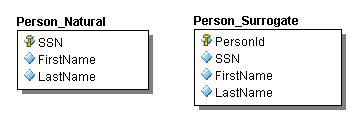
When choosing the primary key for a table, often in designs, natural keys occur in the business problem. For example, if we’re modeling a Person table in our database we might be inclined to use the Social Security number (a natural key) of a person as the primary key in the Person table. This isn’t a bad design, since everyone in the US should have a Social Security number; however, keying the Person table with a Social Security number as the primary key doesn’t lead to an extensible design. What happens if the system and database we’re designing for needs to handle people who are not US citizens or people who don’t have a Social Security number? As you can see, using a Surrogate Key named PersonId with an identity constraint as our primary key is a much better extensible database table design than using a natural key. In most cases, even if the natural key is truly unique, I would still use a Surrogate Key.
That’s all for now! If I come think of some more, I’ll add them to this blog post later. :) Keep in mind there is no “best practice” because any best practice can be turned into a worst practice if the situation changes. The point is the schema design of every database should be well thought out. Being consistent in your designs help leads designs to be readable and maintainable. Extensibility leads your designs to be changed and refactored when business processes change.
Comments
ilahsa
不错,正想学习这个
good,thank your work
Ravi Kumar
Its nice. Thanks!
I have found another article especially for beginners visit http://www.etechpulse.com/2013/05/naming-convention-for-database-design.html
Regards,
Ravi Kumar
Leave a comment
Your email address will not be published. Required fields are marked *